Transcription
A significant amount of descriptive metadata is collected from transcription of the text on the materials.
This text is nearly always handwritten and often difficult to read, resulting in a challenging transcription and validation task. To this point, we have approached transcription with a common sense philosophy and with the goal of transcription to collect metadata that will make materials more searchable, not to capture all stylistic or typographic elements on the page. For example, is it more important for users to be able to identify which column includes the measurements of right ascension, or to have access to all of the algebra notes in the front matter?
The vast majority of records on the plates, envelopes, and logbooks are handwritten by various authors, all with different levels of legibility. Plate writing is done with ink, but is often thick and blobby. Logbooks are often written in pencil, which gets softer and blurrier as it rubs against the page above it. Ink is generally used for writing on envelopes, and envelopes are often created by someone other than the person who has recorded the plate and/or logbook information. The various media present their own challenges for initially recording metadata.
We have not derived an automated solution for handwriting character recognition (either HCR or ICR). We completed some early experimentation with optical character recognition (OCR), and it was unsurprisingly unsuccessful.

Tests with HCR-specific solutions like Transkribus were also unsuccessful. The corpus for Transkribus calibration is the work of Jeremy Bentham, handwritten at least 100 years before the Yerkes material. Perhaps if the Yerkes writing was stylistically closer to Bentham, this test would have produced more positive outcomes. Transkribus demonstrates the viability of a bespoke solution to automation, but we have not explored the possibility of developing a bespoke AI to interpret the Yerkes handwriting in any depth.
Another challenge to automated processes is the tabular nature of the logbooks. Automated transcription of tables is tricky, and non-automated transcription requires more formatting than transcription of narrative-style text. We continue to explore markdown syntax, a system commonly adopted for transcription of tables, and which also facilitates sharing data between systems. Other tabular transcription projects, including the Smithsonian Transcription Center, successfully utilize markdown syntax in their volunteer transcription projects, evidence that it is feasible for transcribers across a wide range of ability. As we continue to codify our transcription process and work with different source materials, the team will also develop a style sheet for transcription that builds upon existing syntax, but also addresses the questions and complications specific to this project.

We must also address the intellectual element of the materials.
While of great importance, the amount of transcribable information on a plate or envelope (and also the time required to transcribe it) is insignificant compared to the amount of transcribable information in a logbook. Aligning with our goals of simplification and searchability, our team made the decision to focus on transcription of information critical to scientific research vs. a faithful transcription of the full material. In practice, this means we are devising methods to transcribe 4–6 types of information from logbooks, plates, and envelopes that capture the specific metadata helpful in searching for particular plate numbers, objects, dates, observers, and locations in the sky. These specific fields will also allow us to link this data with other collections, both in the University’s Library and Archives, but also with international collections as they are simple enough to be crosswalked across various platforms, catalogs, and databases. This strategy also is efficient. Small scale testing indicates that completing a faithful transcription takes nearly 2x as long as a partial transcription as described.
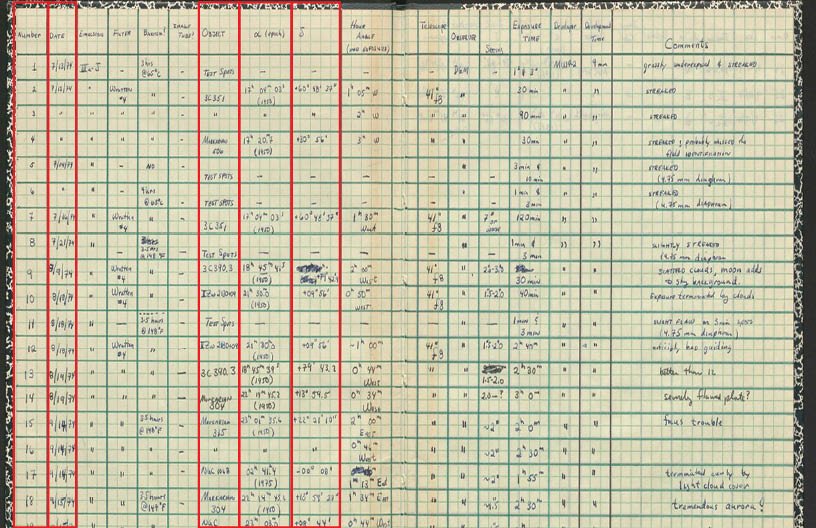
In this logbook, 17 columns record information about the observation and plate used. The red rectangles mark the 5 columns that would be part of the "scientific" transcription of the logbook. They include plate number, date, object, right ascension, and declination.
There are many methods of transcribing, and thus far we have experimented with speech to text and traditional copy typing. The copy typing results are satisfactory – we worked with untrained transcribers for a baseline. There were few errors, but this was an inefficient process that took quite a long time. One of the hurdles of copy typing is that much of the information being transcribed in this case is numeric, making it more difficult to catch mistakes without the support of the spell check feature in word processing programs! We have also researched the feasibility of speech to text transcription, utilizing the Otter.ai application. Currently relying on the free Basic Plan, this speech to text allows us to read the material aloud, then edit the automated transcription produced by the application. This has proven to be a much more efficient process, and we will continue to test its viability over larger sample sizes. There are of course, limitations including that the automatic transcription primarily accommodates English speech to text, so significant editing must occur for many object names, the speech recognition sometimes struggles to interpret different ways of saying numbers (1901 can be said differently – nineteen oh one, nineteen hundred and one – and is also translated as 1901, 19 oh one, 19 o one, etc.), numbers 0–9 are generally written out (zero, one, etc.) and markdown must be applied in the editing process. However, these are relatively simple find-replace edits, and the speech to text process remains promising.
By prioritizing the scientific transcription over the faithful transcription, we are aware that we are leaving out information that might be important or even critical to some researchers, particularly non-science researchers. As a multidisciplinary team, this was a difficult question to parse. At this point, we have decided that metadata for the sake of scientific searchability is the most complicated question to answer, and that we can utilize other methods for other types of information. For example, cataloging keywords could identify logbooks that contain developer formulas, or plates that have scientific markings on them. This strategy of “tagging” themes or markings of interest still allow the materials to be findable while keeping the transcription process efficient.
Of course, there are still questions that surround this data after it is transcribed. For example, we know that at times, the plate, logbook, and envelope record the type of information differently based on the precision of the various instruments and the intent of the recorder – is the declination actually 42º, 42.75º, or 40º? To date, we have chosen to err on the side of too much data rather than too little, and record each of the elements separately. While this does result in competing information, it is possible that the differences are important in understanding the plate historically, or in utilizing the plate for contemporary research. We defer that judgment to the researcher.
Support for this project comes from the National Science Foundation (Grant AST-2101781), University of Chicago College Innovation Fund, John Crerar Foundation, Kathleen and Howard Zar Science Library Fund, Institute on the Formation of Knowledge, and Yerkes Future Foundation.